
guides
Artem Vysotsky
AI OCR Software in 2026: How to Choose Document Extraction That Actually Works
A practical buyer guide to AI OCR software, document extraction, cloud OCR, open-source OCR, LLM vision, and review workflows in 2026.
Read ArticleStay updated on the latest news about AI. Explore insightful articles and tips.
A practical buyer guide to AI OCR software, document extraction, cloud OCR, open-source OCR, LLM vision, and review workflows in 2026.
Read ArticleExplore our collection of articles covering AI tools, productivity tips, and industry insights.
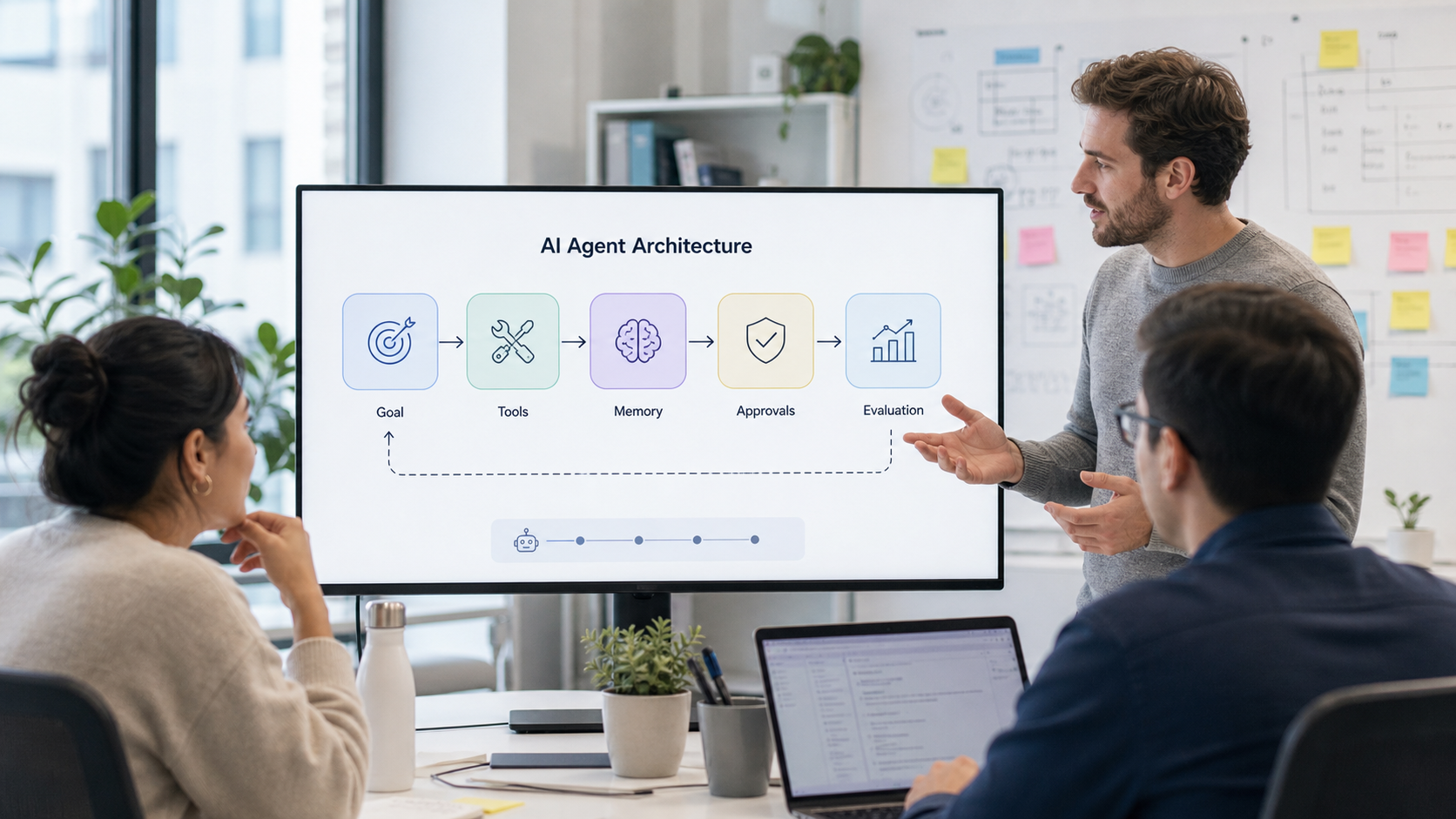





Access 200+ AI models, custom agents, and powerful tools - all in one subscription.