
In this post, we’ll explore the best embedding models—comparing open-source and proprietary solutions—focusing on their performance in search and reranking. We’ll also include detailed tables for clear comparisons and provide useful links for further reading.
What Are Embedding Models and Why They Matter?
Embedding models convert text into vector representations that capture the semantic meaning behind the words. This process is essential for:
Semantic Search: Finding documents based on meaning rather than exact keyword matches.
Reranking: Reordering search results to highlight the most relevant documents.
Using the best embedding models can significantly enhance the performance of your RAG system by improving both the accuracy and efficiency of document retrieval.
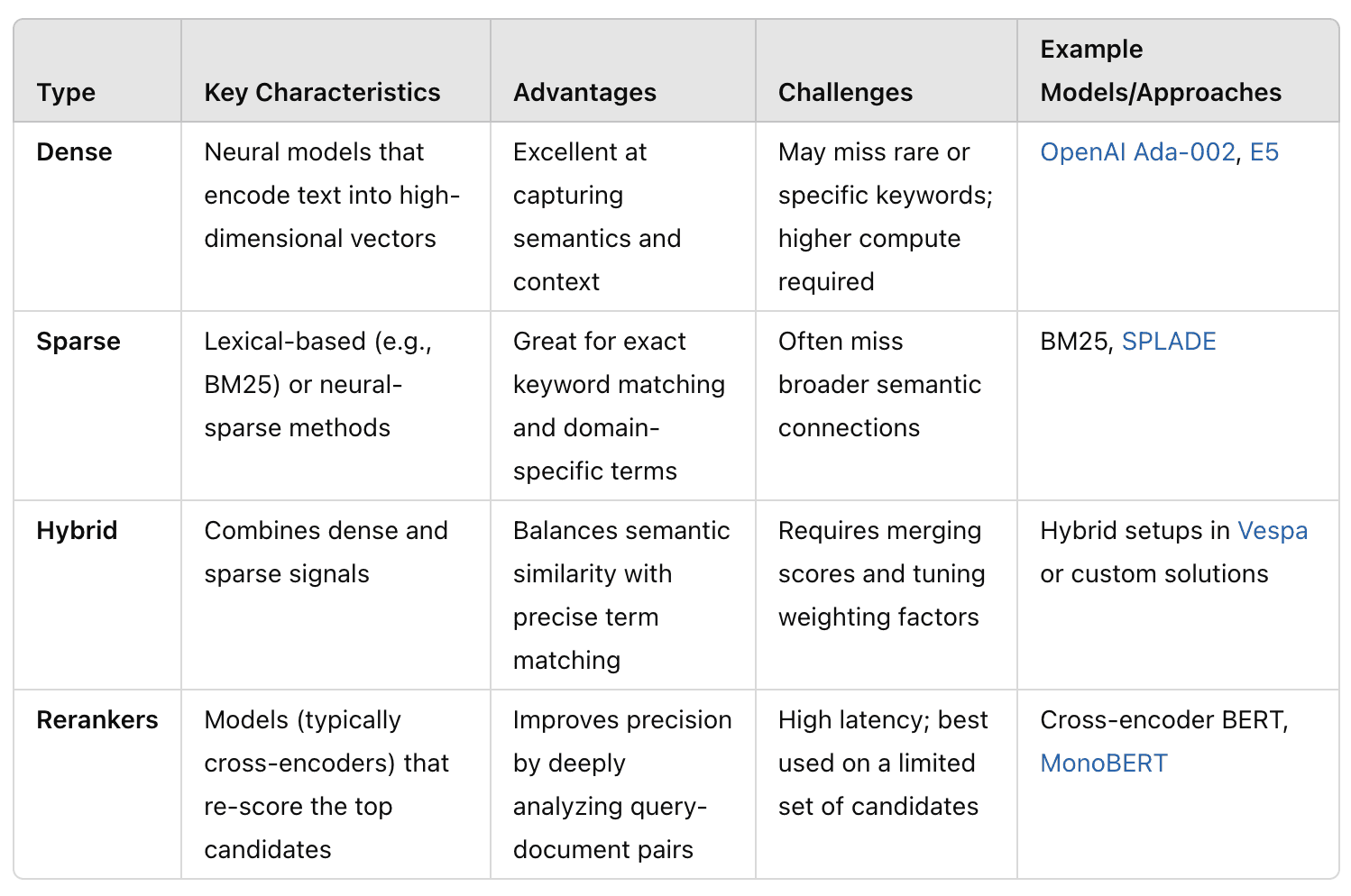
Types of Embedding Models
There are several approaches to generating embeddings. Each type has its own advantages and challenges when it comes to building the best embedding models for your needs:
The Best Embedding Models for RAG
Below is a detailed look at the best embedding models available today, split into open-source and proprietary options.
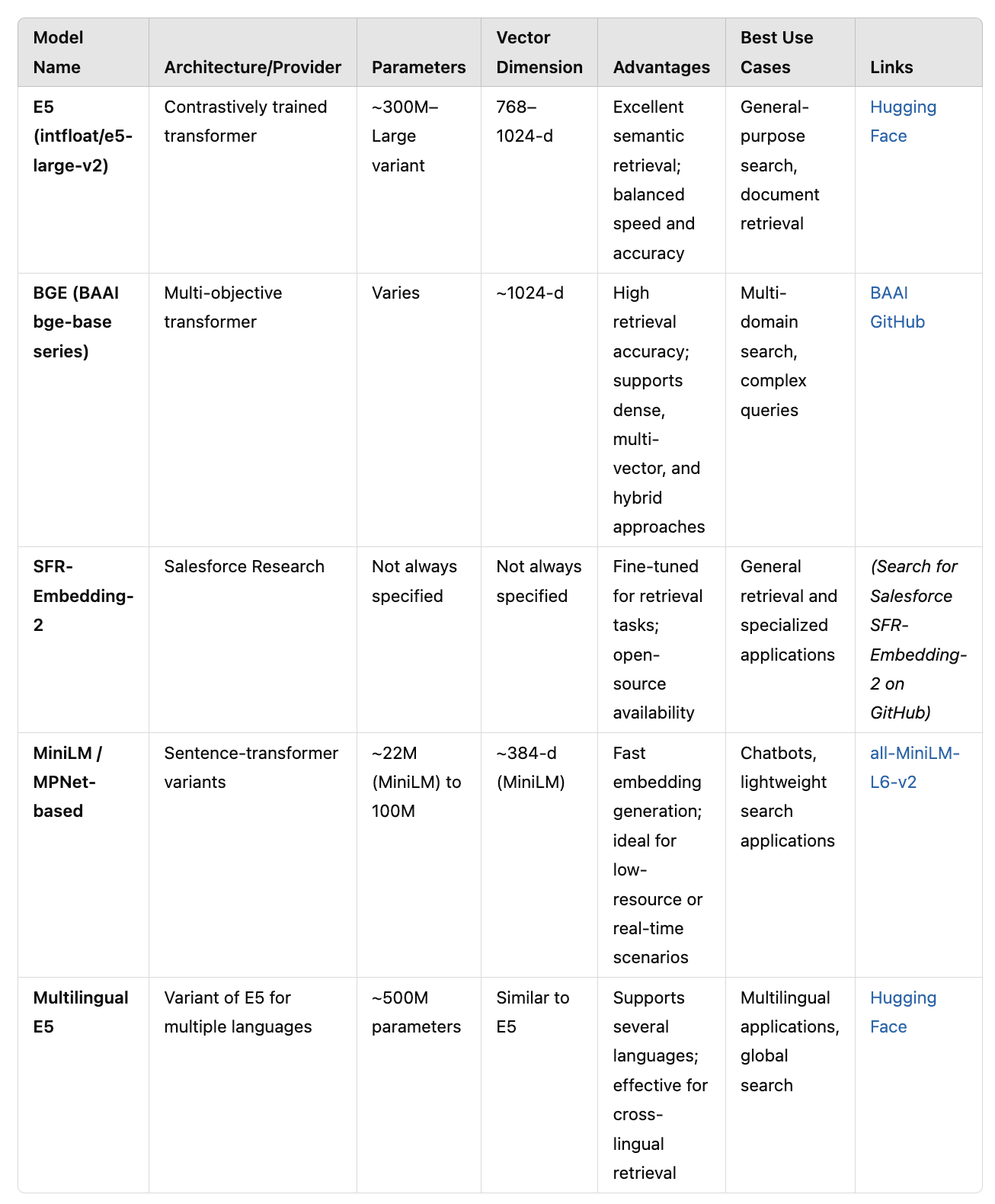
A. Open-Source Models
Open-source solutions offer flexibility and control. Here are some of the best embedding models from the open-source world:
B. Proprietary Models
Proprietary models provide managed infrastructure and high performance right out of the box. Here are some of the best embedding models from leading providers, including OpenAI's latest releases:
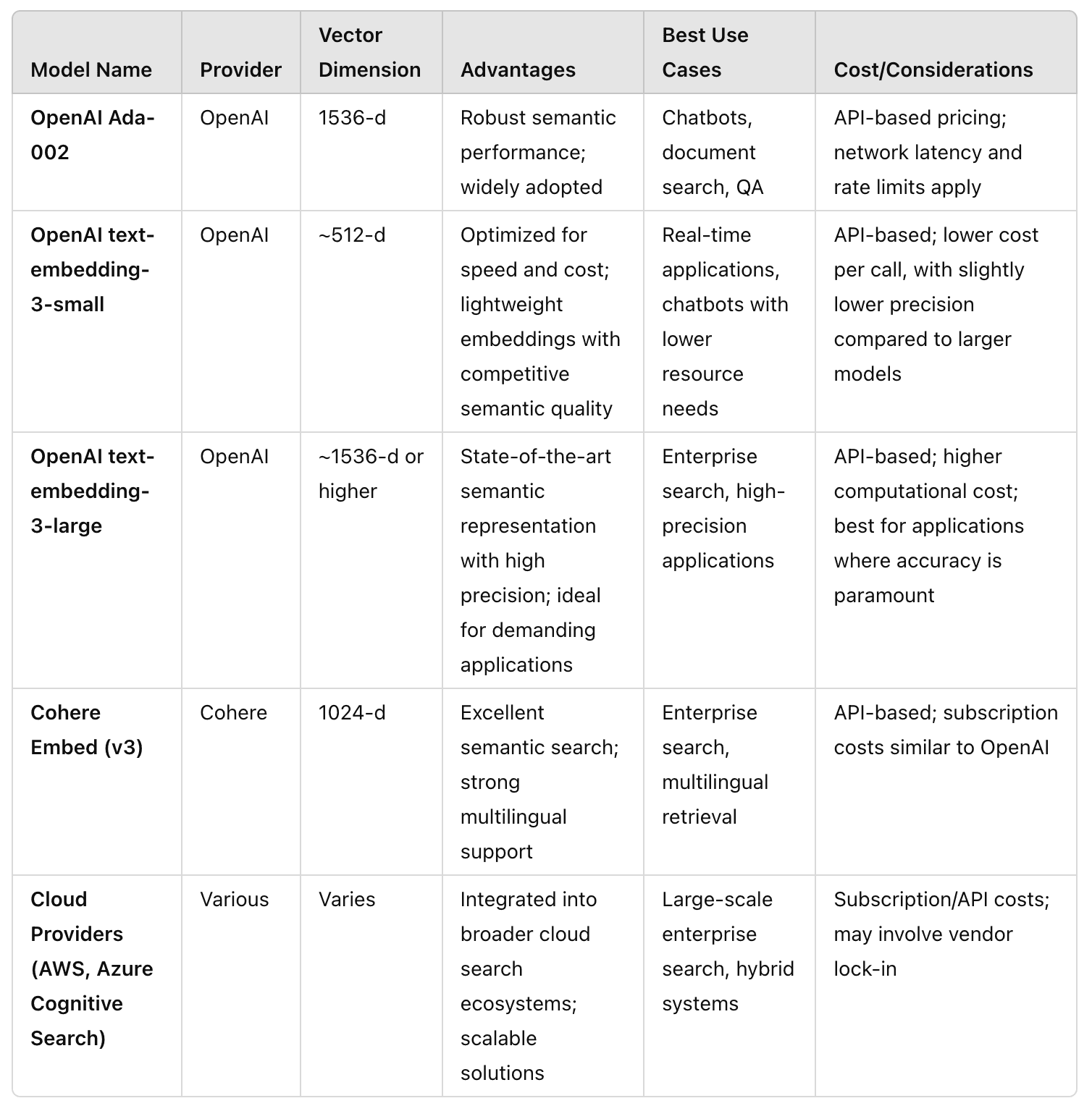
For more details on OpenAI’s embedding models, check out the OpenAI Embeddings Documentation.
Integrating the Best Embedding Models into Your RAG System
Modern RAG pipelines leverage frameworks and vector stores to manage and query embeddings efficiently. Here’s an overview of tools that help integrate the best embedding models into your applications:

Summary and Recommendations
Dense Models: These are among the best embedding models for capturing semantic meaning. Choose solutions like E5 or proprietary options such as OpenAI’s Ada-002 and text-embedding-3-large for high-quality semantic search.
Sparse Models: Ideal for exact keyword matching. Methods like BM25 or neural-sparse approaches (SPLADE) are key when term precision is crucial.
Hybrid Approaches: Combining dense and sparse methods often produces the best results, especially for complex datasets. Platforms like Vespa support such setups.
Rerankers: For applications where precision is paramount, integrating cross-encoders like MonoBERT can refine the ranking of your results.
Integration: Tools like LangChain and vector databases such as FAISS or Milvus enable you to build scalable, efficient RAG systems using the best embedding models available.
Choosing the right model depends on your specific requirements, whether that’s domain specificity, real-time performance, or scalability. Evaluate these models using real-world benchmarks to find the perfect balance of accuracy, efficiency, and cost for your project.
Links and References
OpenAI Embeddings Documentation:
https://platform.openai.com/docs/guides/embeddingsE5 Model on Hugging Face:
https://huggingface.co/intfloat/e5-large-v2Multilingual E5 on Hugging Face:
https://huggingface.co/intfloat/multilingual-e5-largeBGE (BAAI) GitHub Repository:
https://github.com/FlagOpen/FlagEmbeddingSPLADE GitHub Repository:
https://github.com/naver/spladeall-MiniLM-L6-v2 on Hugging Face:
https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2OpenAI Ada-002:
https://platform.openai.com/docs/guides/embeddingsCohere:
https://cohere.aiLangChain:
https://langchain.comFAISS GitHub:
https://github.com/facebookresearch/faissMilvus:
https://milvus.ioVespa:
https://vespa.aiWeaviate:
https://weaviate.io
Frequently Asked Questions
Sources
Written by
Artem Vysotsky
Ex-Staff Engineer at Meta. Building the technical foundation to make AI accessible to everyone.
Reviewed by
Sergey Vysotsky
Ex-Chief Editor / PM at Mosaic. Passionate about making AI accessible and affordable for everyone.


