
Modern coding tools use AI “language models” to write and fix code. These LLMs (large language models) have learned from huge code libraries. They can autocomplete code, suggest fixes, or even build small apps from descriptions. This boosts coding accuracy (fewer bugs) and speed (big chunks of code appear instantly). For example, AI tools can catch many errors early & generate whole functions quickly. They also help beginners by giving instant tips.
Here is a simple comparison of top coding models. It shows key strengths and scores on code tests:
Model | Context | Coding Strengths |
|---|---|---|
GPT-4.5 Turbo (OpenAI) | ~128k tokens | Very accurate on coding tasks (~88% pass@1 on HumanEval). Strong understanding of natural language instructions. |
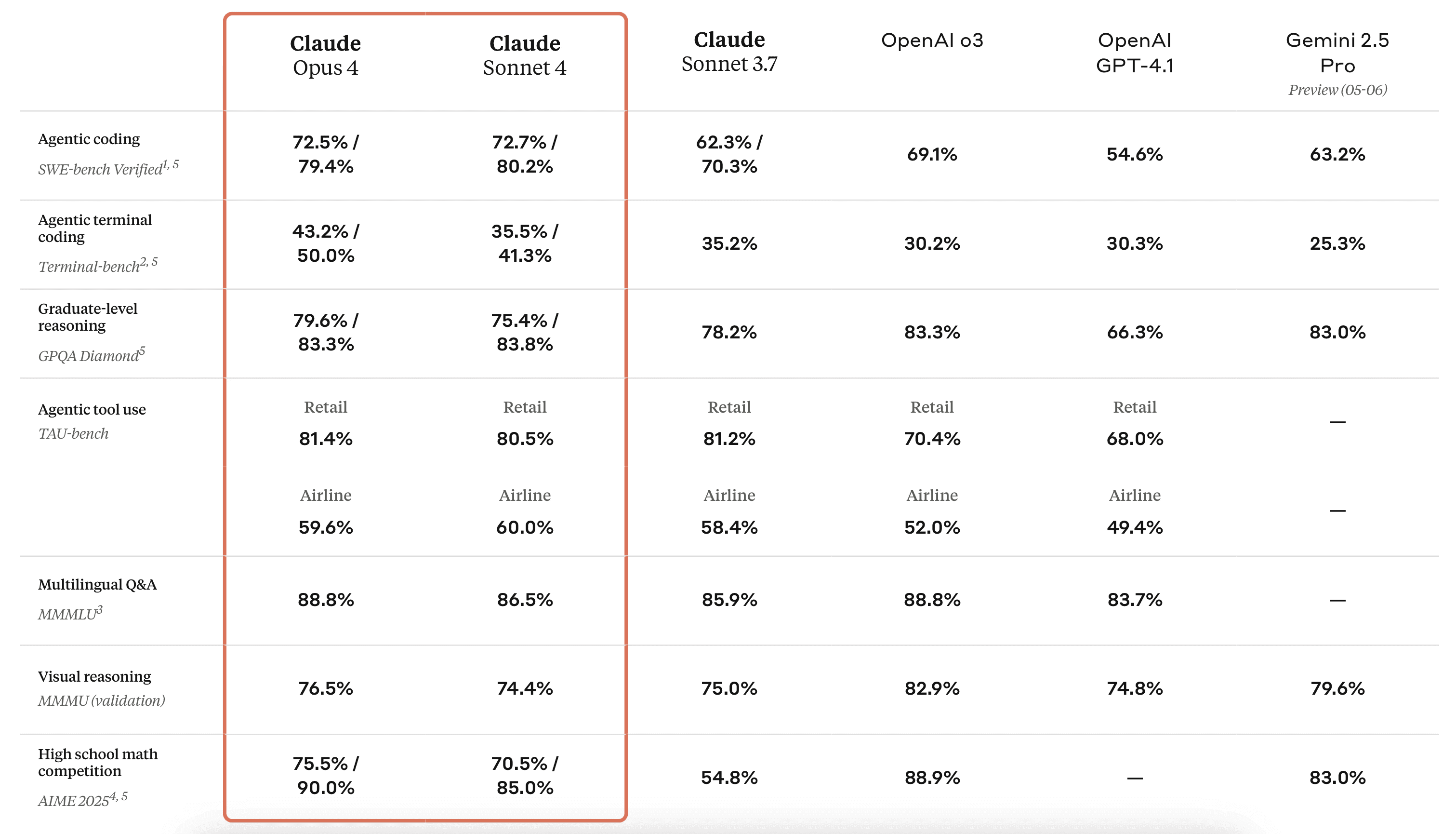
Claude 4 Opus/Sonnet (Anthropic) | 200k+ tokens (extended) | World’s top code model (leads on real-code test SWE-bench at 72.5%). Good for complex, multi-step coding. |
Google Gemini (Flash) | 1M+ tokens | Huge context. Excels at reasoning and coding; new Gemini 2.5 scores 99% on HumanEval. Geminis often top knowledge tests (MMLU68%). |
LLaMA 4 Maverick (Meta) | 1M tokens (max) | Open-source model with very large memory (Scout version reaches 10M tokens). About 62% on HumanEval, but free to run and customize. |
DeepSeek R1 (DeepSeek) | (MoE model) | Open-source, fine-tuned for reasoning. On public tests it matches GPT-4 on math and coding (e.g. SWE-bench). |
Mistral 7B / Mixtral (Mistral AI) | 1M tokens | Small and a bit outdated open model (~7B) that “approaches CodeLlama 7B performance on code”. Outperforms similar-size models on many tasks, including coding. Team is working on something new now. |
O3 Mini | ~128k tokens | Fast, accurate, cost-efficient: optimized for coding, math, STEM; supports function-calls & structured outputs. |
Each model has pros and cons. GPT-4.5 is very precise and friendly for mixed tasks. Claude 4 (Opus and Sonnet) leads on real developer tasks, according to Anthropic (72–73% on SWE-bench). Google’s Gemini series (Flash and Pro) pushes reasoning and code even further (the latest Gemini 2.5 sees ∼99% on HumanEval. Meta’s Llama 4 Maverick gives you an open model with a huge memory (1,000,000 tokens), but many users are not too satisfied with it. Still, you recieve its perks and cons with lightly lower raw code source. Models like DeepSeek R1 and Mistral 7B are open-source alternatives with strong math and logic skills so I still consider them among those top code llm options.
Why AI Helps in Coding
Let me just share my experience and say that AI-assisted coding has at least those three clear pros:
Fewer Bugs: llms for coding can spot likely errors or suggest fixes before you even run the code. This error reduction cuts down debugging time.
Faster Development: These LLMs can swiftly write large segments of code from prompts (like “make a user login system in Python”), shortening project timelines.
Learning Aid: For beginners, AI acts like a tutor, giving instant feedback. It can also explain code (with ease!) & suggest improvements. This is often helping newcomers code better.
Overall, AI code tools free developers to focus on the big picture (architecture, logic) while the model can do all kinds of boilerplate and routine details that you don't want to waste time on.
Top Coding LLMs (Mid-2025)
Let’s look at the strongest models for coding today, including their latest versions and benchmark scores:
GPT-4.5 Turbo (OpenAI)
OpenAI’s newest chat model, GPT-4.5 Turbo, is trained heavily on code. It beats GPT-4 on many tasks. For example, on the HumanEval coding benchmark it solves a high fraction of Python problems, nearly 88% pass. In tests of real programming tasks, GPT-4.5 also outperformed GPT-4o (an older GPT-4 variant). However, on raw coding challenges that require tricky algorithms (“SWE-Bench Verified”), some specialized models (like o3-mini) still edge it out.
Use case examples: GPT-4.5 is great for general coding and I would say it suits beginners well enough. You can give it detailed natural-language instructions (e.g. “write a web scraper in JavaScript”) and it usually produces correct, clean code. It’s also better at understanding comments and documentation prompts than earlier models. Many developers use it for writing new features, refactoring code, or even generating text explanations of code.

Claude 4 (Anthropic Opus & Sonnet)
Anthropic’s Claude 4 now comes in two versions: Opus 4 and Sonnet 4. Both are hybrid models. Claude Opus 4 is billed as “the world’s best coding model,” and it shines at long, complex programming tasks. In fact, Anthropic reports Opus 4 leads the SWE-bench coding test at 72.5% success rates. In my opinion, Sonnet is great for most coding tasks. So, sonnet 4 is slightly smaller but still state-of-the-art; it scored 72.7% on the same benchmark.
Claude models also have very large memory and “extended thinking” modes. They can work for minutes or hours on a task (like refactoring a multi-file project) without losing track. These models also power tools like GitHub Copilot’s new Claude-based agent (released 2025). Is this one in the top of best llms for coding? In my experience, it is in so many ways.
Use cases: If you’re fixing bugs in a big codebase or writing complex algorithms, Claude 4 is a top choice. It does well at end-to-end coding: planning a feature, writing code, running tests, and adjusting. For example, developers say Claude 4 can follow multi-step instructions and make careful edits across multiple files. Sonnet 4 is faster and free on Anthropic’s API, while Opus 4 can run longer “extended thinking” sessions. Both handle 64K tokens of output, making them great for large outputs (like generating whole classes or scripts), that makes Claude recent models good coding llms.
What about o3 Mini for coding?
The o3-mini is OpenAI’s compact “o-series” model, released on January 31, 2025, and designed specifically for coding, math, and STEM tasks. Compared to older GPT models, it’s 24% faster, more accurate, and much cheaper to run in my experience. You can just use it in ChatGPT (free, Plus, Team, and Pro tiers), through the API, where it supports function calling, structured outputs, and even developer messages or inside Writingmate alongside over three hundred other top LLMS / AI Models. Tweaked versions like o3-mini-high can give even stronger performance on logic-heavy or some competitive programming tasks. Its speed, smart function–level reasoning, and low cost make it well suitable for daily code generation, debugging, or algorithm challenges of many sorts.
Google Gemini (Flash & 2.x)
Google’s Gemini line (successor to Bard) now has models like Gemini 1.5 Flash (released Sept ’24) and even newer Gemini 2.0/2.5 (early 2025). These models excel at reasoning and code. For instance, Gemini 1.5 Flash scores quite well on general tests (f.e. MMLU ~0.68 or 68%. It also gives users a useful 1,000,000-token context window. So it can exacute huge prompts or code bases, just paste it into Gemini on original chatbot or Writingmate.ai which gives access to all top models in single chatbot with a lot more of useful features. Try out for free with no card needed.
By May 2025 Google has preview versions (Gemini 2.0/2.5) that blow past 1.5. A recent report shows Gemini 2.5 Pro (June ’25 preview) hits ~99% on HumanEval and that is meaning it solved almost all the test problems. That is comparable to top OpenAI models.
Use cases: Gemini is a strong all-rounder. Its huge context is great for full-app tasks (like generating a multi-page website or complex game logic). Gemini also has strong math/logic, so it can plan algorithms before coding. Google’s tools can even generate SQL queries or complex scripts from plain language. The Flash versions have a decent relation of speed and cost, while the Pro versions push pure quality (but may cost more). Overall, Gemini is still great for code that needs complex reasoning or very large instructions.

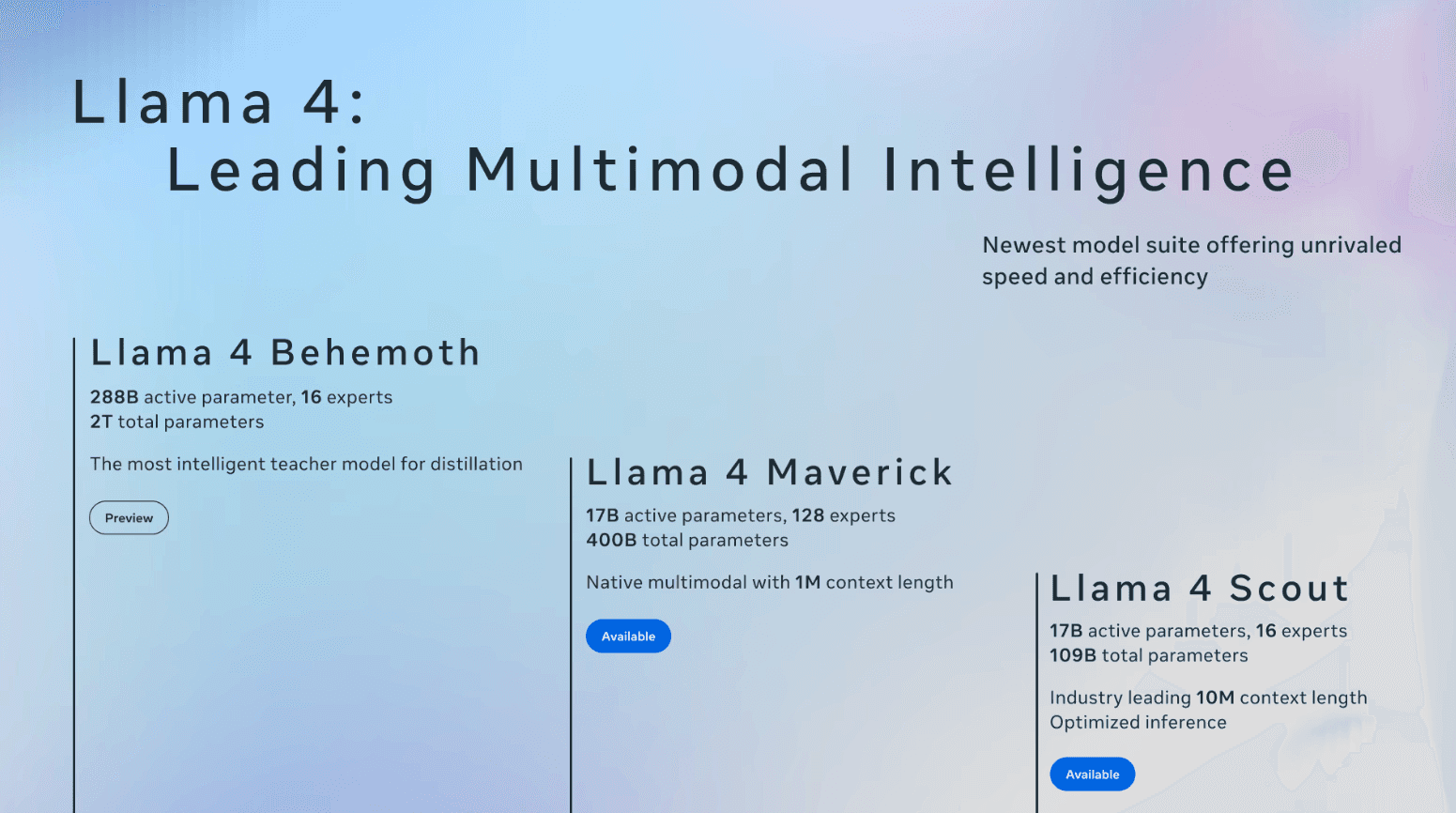
LLaMA 4 Maverick (Meta AI)
Meta’s LLaMA 4 series is now targeted at more of high-end users. LLaMA 4 Maverick (released in April 2025) is an open-source model with up to 1,000,000 token context window. So, that means it can read and write enormous code files. There is also Behemoth model, that is even more impressive than that. Maverick also supports images (for multimodal apps). Importantly, LLaMA 4 Maverick is open-source (Apache 2.0), so developers can run it on their own hardware without API fees. A sibling model, LLaMA 4 Scout, even allows 10,000,000 token context (for gigantic projects).
In coding benchmarks LLaMA 4 Maverick scores around 62% on HumanEval. That’s lower than closed models, but still solid. Because it’s open, teams can fine-tune it on private codebases or build specialized coding assistants.
Use cases: LLaMA 4 is ideal for companies or hobbyists who want full control. You could fine-tune it on your own project’s code to make it even smarter for your needs. It’s also great for “long-context” coding: for example, an AI assistant that remembers an entire 10,000-line codebase. If you value privacy or customization, open Llama models are top choices.
Pro tip: f you need a model that is faster and more cost-effective, try Llama 4 Scout. It is also avaliable on writingmate.ai as well as Maverick LLM. No API keys needed, start for free or at 9 dollars per month.
DeepSeek R1 (Open Source)
DeepSeek-R1 is an open-source model fine-tuned for reasoning and code. It’s based on a mixture-of-experts (MoE) architecture. According to its developers, R1 “achieves results on par with OpenAI’s o1 model on several benchmarks, including MATH-500 and SWE-bench. In other words, on math problems and coding tasks it can match GPT-4’s performance. Independent sources even rank it #1 in coding and math tasks among tested models.
Use cases: DeepSeek-R1 is great if you want an open model specifically pushed to think deeply. It can solve complex algorithmic problems well. Some testers note it can outperform Claude-3.5-Sonnet and older GPT-4 on certain tasks. You could use R1 for code generation, math-heavy development (data science code), or anywhere you need a self-improving model. And since it’s open, the code community is releasing variations distilled to other open models (Llama, Qwen) to share this capability widely.
Here is a brief comparison I just written of DeepSeek R1 vs OpenAI o3 Mini: writingmate.ai/blog/openai-o3-mini-vs-deepseek-r1-comparison

Mistral 7B (and Mixtral)
Mistral AI’s Mistral 7B (released not so recently, in late 2023) is a 7.3B open model that punches well above its weight. It beats Llama 2 13B and people still use it for coding because of its open-source, indie nature and adaptability. In coding, the Mistral team shows it is “vastly superior in code and reasoning benchmarks” compared to similar modelsmistral.ai.
There’s also Mixtral 8×7B. It is a kind of mixture-of-experts (MoE) version with 8 experts that further boosts power (weights total ~64B). It’s known to be very strong on code and math (still, similar to GPT-4 levels).
Use cases: Mistral and Mixtral are still decent if you want a high-performance open model and have resources to run them. They’re very efficient, so inference (generating code) can be faster and cheaper than running larger models. Developers use them for on-device coding assistants, or for research. Mistral Instruct (fine-tuned for chat) even outperforms other 7B chat models on standardized tests. In short, they give you near-state-of-the-art accuracy in an open package. Mistral models with various configurations are also avaliable on writingmate.ai.

Real-World Coding Uses
Developers use these AI models in so many ways. Let me name just five of them.
Building Apps & Prototypes: Quickly scaffold entire applications. For example, you can describe a simple game or app (“make a quiz app with login”) and get HTML/JavaScript or Python code in seconds. Tools like Writingmate provide no-code builders where you write prompts and get ready-to-run pages (you can even export HTML). This lets you prototype ideas fast without manual coding. Other article we done on that topic: https://writingmate.ai/blog/what-llm-to-use-for-coding-the-power-of-ai-models.
Debugging & Refactoring: Instead of manually tracking down an error, you can ask the LLM to review your code. It often spots logic bugs or syntax issues and suggests fixes. For instance, you might paste a Python function, say it’s not returning correct results, and the model will find the off-by-one mistake or missing condition.
Competitive Programming: AI can assist with contest problems. Benchmarks like CodeContests/APPS measure this ability. Modern models can solve many algorithmic puzzles (sorting, searching, dynamic programming) quickly. High-end LLMs now achieve ratings beyond 2000 on Codeforces problems (better than most human coders). In practice, a student might describe a Codeforces problem and the model returns a working solution template. This can speed up practice sessions.
Learning & Pair-Programming: Even experienced coders use LLMs as pair programmers. You might use “vibe coding” – a new approach where you keep asking the AI to change or extend code. Instead of writing each line, you talk: “make this function faster” or “add a save-to-database feature”. The model updates the code iteratively. This lets you build complex features step-by-step, almost like talking to a junior dev. (As Andrej Karpathy put it, you focus on saying what you want, and the AI writes the code.
Multimodal & Creative Coding: Some LLMs also handle images (like GPT-4 Vision, Gemini with images, or Stable Diffusion for graphics). You could generate a UI design image with Stable Diffusion and then ask the code model to create HTML/CSS for it. Writingmate even lets you use vision models like Flux.ai or Stable Diffusion side-by-side with coding LLMs to go from mockups to code seamlessly.
In all these cases, having an accurate model is key. Benchmarks like HumanEval (coding tasks), GSM8K (math), and BigBench (broad skills) show which models get syntax and logic right more often.
For example, Gemini 2.5’s near-99% HumanEval score still means it makes fewer mistakes on average, while Claude 4’s top SWE-bench result given by Anthropic also means it can work with real software challenges reliably (most of the time).
Writingmate’s own tools let you switch between these models in one click. You can finally try the same prompt on GPT-4o, o3-mini Claude 4, Gemini Flash, LLaMA 4 Maverick, etc., and see which gives the best result. There is side-by-side model comparison, and possibility to use any of 300+ models included, while also having a very simple to use interface and various additional features like Prompt Libraries and AI Agents. Such a multi-model access is very useful to most users, because one model might be best at algorithms, another at web code, and another at reasoning about requirements. Try it out for free here:
Conclusion
In summary, the best LLM for coding depends on your needs. OpenAI’s GPT-4.5 Turbo and Google’s Gemini 2.x lead on many benchmarks and handle complex logic well. Anthropic’s Claude 4 Opus/Sonnet shine on real-world software tasks. Open models like LLaMA 4 and DeepSeek R1 give you customization and privacy with still very strong results.
The table above and the explanations should help you pick the right top code LLM for your project. Remember that benchmarks like HumanEval or SWE-bench give a numerical snapshot, but actual performance also depends on your prompt and use case. In practice, using a mix of models often works best: one for writing core logic, another for language explanations, another for rewriting code.
Finally, remember that Writingmate lets you experiment with all these AI helpers in one place (it replaced the old “ChatLabs” app). Writingmate supports GPT-4.5 Turbo, Claude 4, Gemini Flash/Pro, LLaMA 4 Scout/Maverick, and even image models like Flux.ai and Stable Diffusion in the same interface. You can switch models freely to see, which one finally gives you the right “vibe” in any code of yours.
Happy coding with AI!
See more articles on writingmate.ai/blog. See you!
Frequently Asked Questions
Sources
Written by
Artem Vysotsky
Ex-Staff Engineer at Meta. Building the technical foundation to make AI accessible to everyone.
Reviewed by
Sergey Vysotsky
Ex-Chief Editor / PM at Mosaic. Passionate about making AI accessible and affordable for everyone.


